💻 Programming (프로그래밍)/Python
[Python] 이미지 크롤링 - Selenium
- -

- Install
명령어를 친 후 셀레니움을 설치해줍니다.
저는 Anaconda를 이용하여 가상환경을 미리 만들고 설치하였습니다.
conda install selenium
이후에 자기가 원하는 브라우저의 WebDriver이 필요합니다.
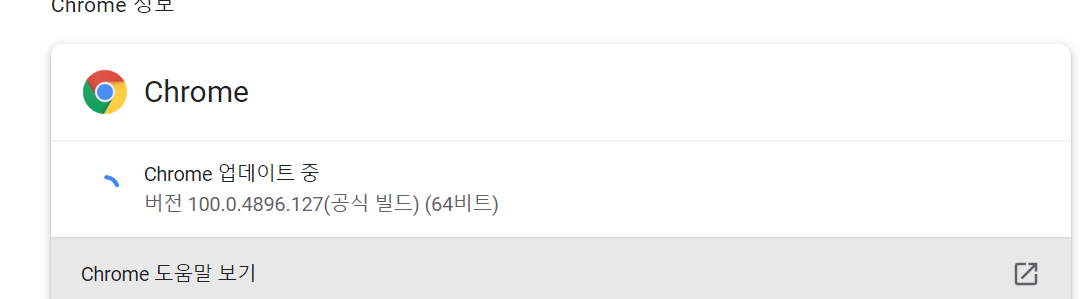
브라우저의 정보에서 버전을 알 수 있습니다.
ex) 크롬의 경우 , 오른쪽 위 점3개 - 도움말 - Chrome 정보를 통해 들어가면 알 수 있습니다.
이후, webdriver을 selenium 의 파이썬 파일과 같은 디렉토리에 둡니다.
- Import
이미지 크롤링을 사용한 방법만 적겠습니다.
아래의 저희가 사용할 라이브러리를 불러와줍니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from urllib.request import Request, urlopen
import urllib.request
import os- Driver Option
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")webdriver.ChromeOption() : 웹드라이버의 옵션을 설치할 클래스 객체 설정
options.add_experimental_option() : url open 이후, 로그를 노출시키지 않게 해줍니다.
webdriver.Chrome(options=options) : webdriver 크롬버전 클래스 객체 할당
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl") : 구글 이미지 사이트 열기
- Image Crawling
elem = driver.find_element_by_name("q")
#name = '검색어'
if not os.path.exists(name):
os.makedirs(name)
elem.send_keys(name)
elem.send_keys(Keys.RETURN)
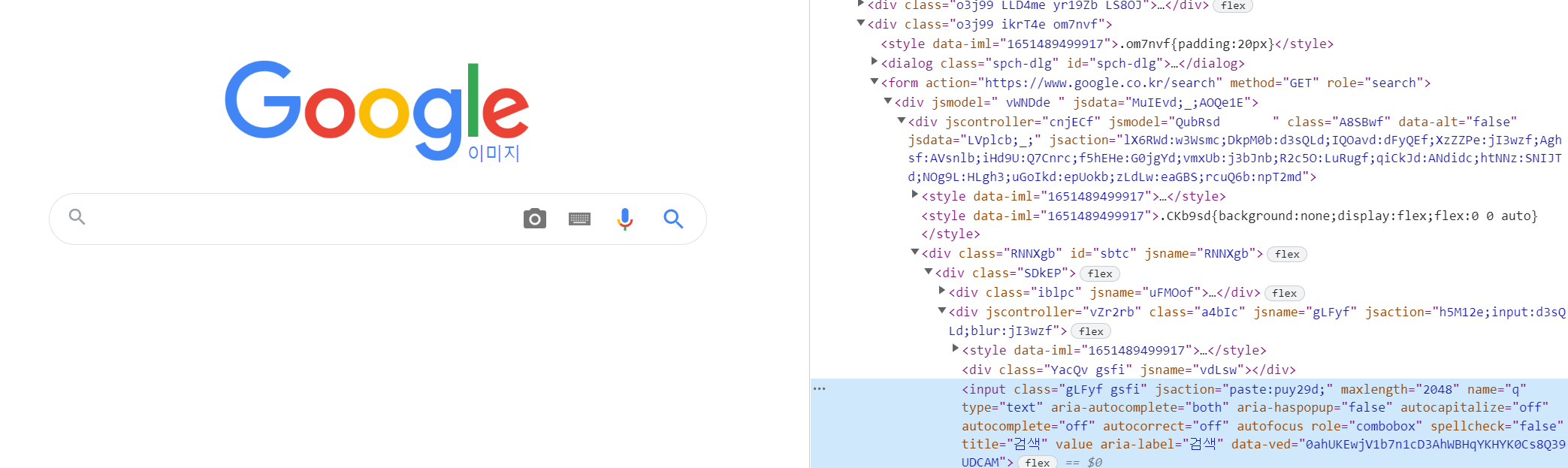
타이핑을 칠 수 있는 검색창의 name은 "q"로 되어 있어,
driver.find_element_by_name("q") 을 통하여 엘레멘트 값을 가져와줍니다.
이후 저는 os를 이용하여, 저장할 디렉토리를 만들어줍니다.
다음 send_keys("검색어")을 이용하여 검색어를 타이핑 한 후
send_keys(Keys.RETURN)을 이용하여 엔터를 눌러줍니다.
이후 이미지를 스크롤 끝까지 내려 이미지가 없을때까지 로딩해줍니다
SCROLL_PAUSE_TIME = 1
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
count = 1
output_path = './' + name +'/'
driver.execute_script("return document.body.scrollHeight")
: 현재 화면 웹페이지 높이를 자바스크립트를 통하여 리턴해줍니다.
driver.execute_script("window.scrollTo(0, document.body.scrollHeight))
: 브라우저 끝까지 내리고 시작합니다.
스크롤을 내리다보면 결과더보기가 생길 때가 있는데, 이때
driver.find_element_by_css_selector(".mye4qd").click() 를 통하여 클릭해줍니다.

이후, while 반복문을 통하여 스크롤을 끝까지 내려줍시다.
그 다음 images 변수속에 사진 리스트를 넣어줍시다.
for image in images:
try:
webdriver.ActionChains(driver).move_to_element(image).click(image).perform()
time.sleep(1.5)
imgUrl = driver.find_element_by_css_selector('.n3VNCb').get_attribute('src')
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(imgUrl, output_path + str(count) + ".jpg") // 경로대로 이미지 다운로드
count = count + 1
except:
pass
driver.close()이후 ActionChains(driver).move_to_element(image)를 이용하여 연속적으로 마우스를 열심히 옮겨줍니다.

이후 url을 가지고와 다운로드 받을 수 있는
opener을 가지고와서, 열심히 저장해주면 됩니다.
오프너를 쓰는 이유는, 다운로드 할 때, 특정 사이트의 경우 봇이 접근하는 것을 차단하여
인간인 것 처럼 속이는 headers을 추가하면, 정상적으로 크롤링이 가능하다고 합니다!
최종코드
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from urllib.request import Request, urlopen
import urllib.request
import os
def Crawling(name):
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
elem = driver.find_element_by_name("q")
#name = '됭경모치'
if not os.path.exists(name):
os.makedirs(name)
elem.send_keys(name)
elem.send_keys(Keys.RETURN)
SCROLL_PAUSE_TIME = 1
# Get scroll height
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# Scroll down to bottom
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait to load page
time.sleep(SCROLL_PAUSE_TIME)
# Calculate new scroll height and compare with last scroll height
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
try:
#driver.find_element_by_css_selector(".r0zKGf").click()
driver.find_element_by_css_selector(".mye4qd").click()
except:
break
last_height = new_height
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
count = 1
output_path = './' + name +'/'
for image in images:
try:
# image.click()
# element = driver.find_element_by_css('div[class*="loadingWhiteBox"]')
webdriver.ActionChains(driver).move_to_element(image).click(image).perform()
time.sleep(1.5)
imgUrl = driver.find_element_by_css_selector('.n3VNCb').get_attribute('src')
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1941.0 Safari/537.36')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(imgUrl, output_path + str(count) + ".jpg")
count = count + 1
except:
pass
driver.close()
# ---------------------- 코드 실행 ---------------------------
Crawling("검색하고 싶은 단어")
'💻 Programming (프로그래밍) > Python' 카테고리의 다른 글
| [Python][업비트 자동매매프로그램] 2. 메인 루프 (0) | 2022.07.13 |
|---|---|
| [Python][업비트 자동매매프로그램] 1. 목업 제작 (0) | 2022.07.12 |
| [Python][Tkinter] 5) list_리스트 (0) | 2021.07.05 |
| [Python][Tkinter] 4) text_entry_글자입력 (0) | 2021.07.05 |
| [Python][Tkinter] 3) Label_레이블 (0) | 2021.07.05 |
Contents
소중한 공감 감사합니다